
At Tracebit, we deploy and monitor security canaries in our customers’ cloud environments to detect potential intrusions. This involves processing a lot of log data, and it’s critical that we do so carefully to enable us to properly detect the 1-in-a-billion events we’re looking for.
When we started looking at Azure canaries, there were quite a few intricacies and inconsistencies in the logs that caught me by surprise. I wanted to share a handful of examples in this blog post. While I had to learn most of these the hard way, I hope that this post will help someone out there who’s interested in monitoring and writing detections against Azure logs!
- Azure logs primer
- Schema inconsistencies
- IP address inconsistencies
- User-agent inconsistencies
- "Unique" name claims
- First party apps not consistently verified
- UUID inconsistencies
- JWT claim inconsistencies
- Blob Storage name inconsistencies
- Conclusion
Azure logs primer
Azure provides a number of monitoring data sources out of the box. At Tracebit we mostly deal with the Azure logs about resources, and so that’s what we’ll focus on here. They come in two flavours:
- The Activity log is managed on a per subscription basis and contains management plane events. Except for a few special cases, only successful operations that change state are included. So, in general, there is no visibility of data being read or principals trying to perform operations for which they don’t have permissions. Activity logs are always enabled.
- Resource logs (previously called diagnostic logs) are managed on a per resource basis and, in general, contain all data plane events for the associated resource (including read events and events that failed due to insufficient permissions). These logs are disabled by default.
Both types of logs can be sent to a few different destinations for archival and analysis.
Schema inconsistencies
For resource logs, there is a common top level schema and a supplementary schema that depends on the Azure service the log came from. However, both the top level and supplementary schema are slightly different depending on where you are sending the logs!

For activity logs, there is a separate set of schemas depending on the event category - except, if you’re sending events to a storage account or event hub, in which case the activity logs conform to the common top level schema for resource logs.

One more thing - if you have historical logs in storage accounts they are in a slightly different format again!
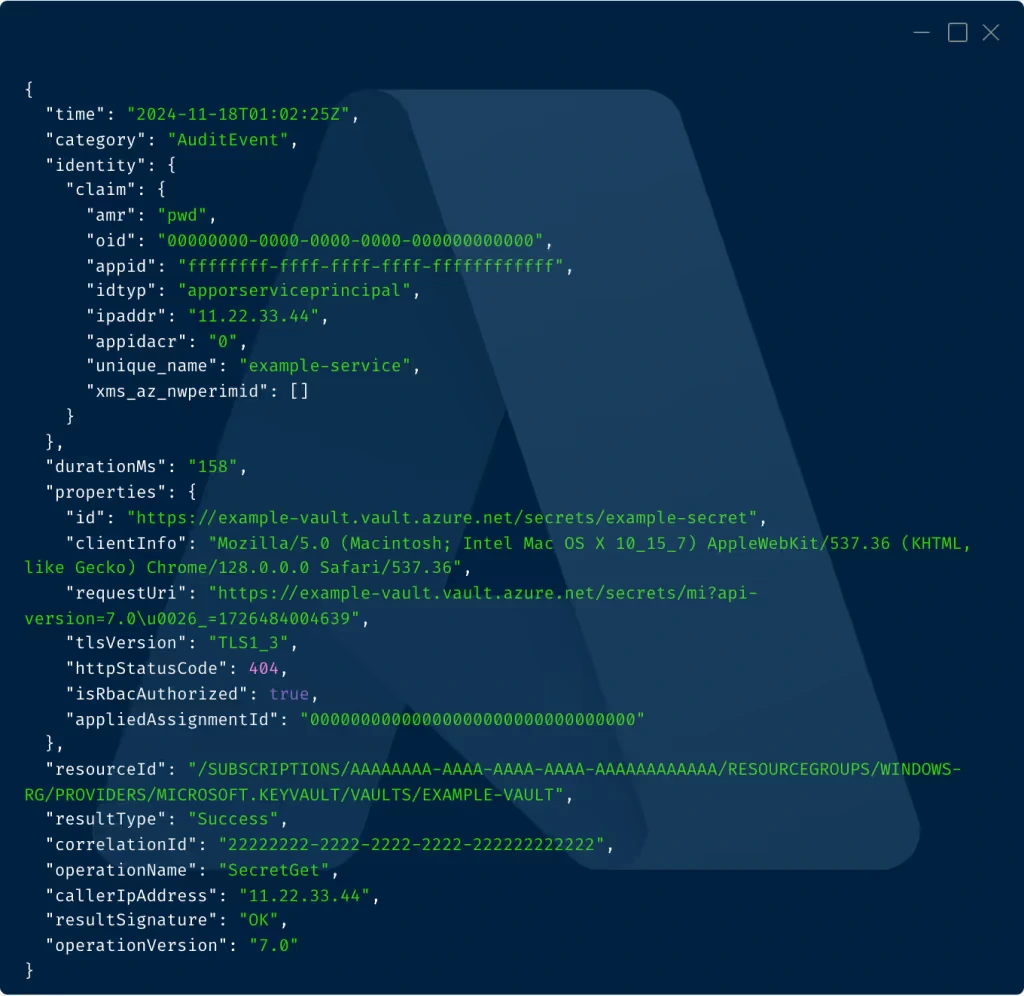
The examples in this blog are based on logs as they appear in Azure Blob Storage post 2018. In particular, this means we should expect all logs to conform to the resource logs common top level schema - we’ll also omit irrelevant fields. Here's an example log:
{
"time": "2024-11-18T01:02:25Z",
"category": "AuditEvent",
"identity": {
"claim": {
"amr": "pwd",
"oid": "00000000-0000-0000-0000-000000000000",
"appid": "ffffffff-ffff-ffff-ffff-ffffffffffff",
"idtyp": "apporserviceprincipal",
"ipaddr": "11.22.33.44",
"appidacr": "0",
"unique_name": "example-service",
"xms_az_nwperimid": []
}
},
"durationMs": "158",
"properties": {
"id": "https://example-vault.vault.azure.net/secrets/example-secret",
"clientInfo": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36",
"requestUri": "https://example-vault.vault.azure.net/secrets/mi?api-version=7.0\u0026_=1726484004639",
"tlsVersion": "TLS1_3",
"httpStatusCode": 404,
"isRbacAuthorized": true,
"appliedAssignmentId": "00000000000000000000000000000000"
},
"resourceId": "/SUBSCRIPTIONS/AAAAAAAA-AAAA-AAAA-AAAA-AAAAAAAAAAAA/RESOURCEGROUPS/WINDOWS-RG/PROVIDERS/MICROSOFT.KEYVAULT/VAULTS/EXAMPLE-VAULT",
"resultType": "Success",
"correlationId": "22222222-2222-2222-2222-222222222222",
"operationName": "SecretGet",
"callerIpAddress": "11.22.33.44",
"resultSignature": "OK",
"operationVersion": "7.0"
}IP address inconsistencies
Let’s start by looking at IP addresses. The common top level schema for resource logs contains an optional callerIpAddress field that is described by Microsoft as:

Taking a look at an arbitrary (administrative) activity log, we find what we would expect - a public IP address:
{
"category": "Administrative",
"operationName": "MICROSOFT.INSIGHTS/DIAGNOSTICSETTINGS/WRITE",
"callerIpAddress": "1.2.3.4",
}However if we take a look at resource logs, we will often (but not always) find something surprising - a port!
{
"category": "StorageRead",
"operationName": "GetBlobProperties",
"callerIpAddress": "1.2.3.4:43200",
}
The main result of this is you cannot perform equality checks on IP addresses as strings, you must first strip the port (being careful not to accidentally strip the last group of an IPv6 address).
Whilst unlikely to cause any issues processing these logs, sometimes we also find that, contrary to the documentation, the IP address might be from a private range:
{
"category": "StorageRead",
"operationName": "GetContainerProperties",
"callerIpAddress": "10.0.3.124:42233",
}User-Agent inconsistencies
User-Agents (UAs) are another commonly used field in security logs. Unfortunately, there is no standard UA field in Azure resource logs and so each service must separately decide how to include it, and they have not all chosen the same method. For example, blob storage defines a properties.userAgentHeader field:

and key vault makes a somewhat vague reference to it in the description of its properties field:

Looking at some logs it turns out to be included in a field called clientInfo:
{
"category": "AuditEvent",
"operationName": "VaultGet",
"properties": {
"clientInfo": "Mozilla/5.0",
}
}Although, only sort of. For logs related to a small number of key vault operations (including VaultGet) only some of the UA is included in the clientInfo field. From my testing, it seems as though Azure is stripping any leading whitespace and then truncating the UA at the next white space character. For example:
This is unfortunate behaviour as spaces are common in UAs and so lots of useful information is lost. I am not quite sure what the purpose of this behaviour is. If anyone reading knows, please do reach out!
"Unique" name claims
As per the resource logs top level schema, logs may contain an identity field that may include information about the claims in various JSON Web Tokens (JWTs).

One such claim can be found at identity.requester.unique_name and represents the unique_name claim that can be found in some v1.0 tokens. However, as per the Microsoft documentation, the unique name is really a ‘display name’, and specifically is not guaranteed to be unique.

First party apps not consistently verified
When processing a log that relates to an application principal, it is sometimes useful to determine if the app is published by a trusted organisation. To allow this Microsoft has a system where publishers can become verified. Since Entra includes Microsoft-owned apps, this also applies to Microsoft itself (as well as third party publishers). Here is an example of the information returned for a Microsoft app by the Azure CLI when I list service principals in a tenancy
$ az ad sp list
...
{
"appDisplayName": "Metrics Monitor API",
"appId": "12743ff8-d3de-49d0-a4ce-6c91a4245ea0",
"verifiedPublisher": {
"addedDateTime": "2024-04-26T17:06:27Z",
"displayName": "Microsoft Corporation",
"verifiedPublisherId": "5206095"
}
}
...Unfortunately, Microsoft does not seem to verify all its apps:
{
"appDisplayName": "Azure Traffic Manager and DNS",
"appId": "2cf9eb86-36b5-49dc-86ae-9a63135dfa8c",
"verifiedPublisher": {
"addedDateTime": null,
"displayName": null,
"verifiedPublisherId": null
}
}In a fresh Azure tenancy, only about ⅓ of the (several hundred) apps you get by default are verified.
Microsoft does publish a list of first party application IDs, but that’s a moving target that you’ll need to stay on top of if you want to verify that an app really is published by Microsoft. Even if you do so, the list itself seems to be focused on Entra logs (rather than activity or resource logs) and is in any case incomplete.

UUID inconsistencies
For most fields, Azure formats UUIDs using dashes, but for some fields it does not. Here is an Activity log where the principal ID is formatted differently under different fields.
{
"category": "Administrative",
"operationName": "MICROSOFT.STORAGE/STORAGEACCOUNTS/LISTKEYS/ACTION",
"identity": {
"authorization": {
"evidence": {
"principalId": "123456789abcdef123456789abcdef12",
}
},
"claims": {
"http://schemas.microsoft.com/identity/claims/objectidentifier": "12345678-9abc-def1-2345-6789abcdef12",
}
}
}The main result of this is the same as for IP addresses: before performing equality checks, you should parse UUIDs into a standard format.
JWT Claim inconsistencies
Logs may include information about claims in various JWTs. Some special claims get dedicated fields (like unique_name discussed previously) while others are included in a generic mapping. In some logs this mapping is under a key called claims, in others the key is called claim (note the missing s). In the mapping, the name of some claims takes the form of a URL whilst others are arbitrary strings. For example when doing a VaultGet the Object ID of the principal is under a ‘URL-style’ claim
{
"category": "AuditEvent",
"operationName": "VaultGet",
"identity": {
"claim": {
"http://schemas.microsoft.com/identity/claims/objectidentifier": "12345678-9abc-def1-2345-6789abcdef12"
}
}
}But when performing a SecretGet it’s in a different, non-URL format, claim
{
"category": "AuditEvent",
"operationName": "SecretGet",
"identity": {
"claim": {
"oid": "c3ccd924-b2a2-46f8-9bf3-ab2e665542e3",
}
}
}Specifically, for the object ID of the principal associated with the log, you should check the “http://schemas.microsoft.com/identity/claims/objectidentifier” or “oid” key in the claims (and claim) mapping and the identity.requests.objectId field.
Having to check multiple claims is, unfortunately, quite common. Another notable example is the human readable name of a user or service principal. In my experience it can be in a URL-style claim ending with “/emailaddress”, “/upn”, “/unique_name” or just “/name”, and possibly more I haven’t discovered yet.
Blob storage name inconsistencies
When sending logs to Azure storage, the name of the blob (also known as its key or path) contains the ID of the resource the logs refer to in the form resourceId=<resource-id>. Depending on the type of the resource, the <resource-id> is sometimes (but not always) capitalised e.g.
resourceId=/subscriptions/00000000-aaaa-0000-aaaa-000000000000/resourceGroups/rg/providers/Microsoft.Storage
/storageAccounts/some-name/blobServices/default/y=2024/m=01/d=01/h=01/m=00/PT1H.json
compared to:
resourceId=/SUBSCRIPTIONS/00000000-AAAA-0000-AAAA-000000000000/RESOURCEGROUPS/RG/PROVIDERS/MICROSOFT.KEYVAULT
/VAULTS/SOME-NAME/y=2024/m=01/d=01/h=01/m=00/PT1H.jsonConclusion
Clearly the logs available in Azure are the result of a huge number of teams working over a number of years. I understand how some inconsistencies - in format, content and documentation - can come about in such an environment. This does however leave quite a lot of work for the consumers of these logs to do if they want to handle them in a consistent way. I hope that some of the tips I’ve highlighted here help - in some small way - someone else out there to get more value out of their Azure logs!
